爬取网页其实就是通过URL获取网页信息,网页信息的实质是一段添加了JavaScript和CSS的HTML代码。
 (资料图)
(资料图)
爬取网页其实就是通过URL获取网页信息,网页信息的实质是一段添加了JavaScript和CSS的HTML代码。Python提供了一个抓取网页信息的第三方模块requests,requests模块自称“HTTP for Humans”,直译过来的意思是专门为人类而设计的HTTP模块,该模块支持发送请求,也支持获取响应。
1.发送请求
requests模块提供了很多发送HTTP请求的函数,常用的请求函数具体如表10-1所示。
表10-1 requests模块的请求函数
2.获取响应
requests模块提供的Response 类对象用于动态地响应客户端的请求,控制发送给用户的信息,并且将动态地生成响应,包括状态码、网页的内容等。接下来通过一张表来列举Response类可以获取到的信息,如表10-2所示。
表10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块抓取百度网页,具体代码如下:
# 01 requests baiduimport requestsbase_url = "http://www.baidu.com"#发送GET请求res = requests.get (base_url)print("响应状态码:{}".format(res.status_code)) #获取响应状态码print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式res.encoding = "utf-8" #更新响应内容的编码方式为UIE-8print("网页源代码:\n{}".format(res.text)) #获取响应内容以上代码中,第2行使用import导入了requests模块;第3~4行代码根据URL向服务器发送了一个GET请求,并使用变量res接收服务器返回的响应内容;第5~6行代码打印了响应内容的状态码和编码方式;第7行将响应内容的编码方式更改为“utf-8”;第8行代码打印了响应内容。运行程序,程序的输出结果如下:
响应状态码:200编码方式:ISO-8859-1网页源代码:百度一下,你就知道 …省略N行…
值得一提的是,使用requests模块爬取网页时,可能会因为没有连接网络、服务器连接失败等原因导致产生各种异常,最常见的两个异常是URLError和HTTPError,这些网络异常可以使用 try…except 语句捕获与处理。
上一篇:世界最新:李兴禹最新小说_李兴禹
下一篇:最后一页
- 海澜之家(600398):短期环比改善 长期战略引领、革新向前 前沿热点
- 绿地控股:筹划非公开发行股票 募资用于保交楼相关项目
- 准新郎酒驾被查 没想到这已经是第四次了
- @千万郑州人,今后非机动车违法采取新办法,需现场朗读“承诺书”
- 4月河南物价水平保持温和上涨
- 被车评人集体声讨的保时捷终于妥协:免费恢复功能,延保一年
- 郑州市经开区率先部署15分钟核酸检测“采样圈” 记者实探经北一路核酸采样工作站
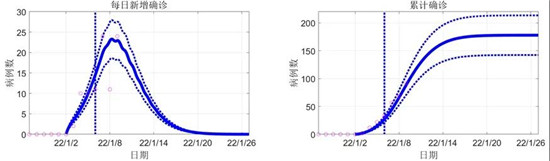
- 最新全国疫情中高风险地区名单:全国现有高中风险地区15+64个(统计时间:5月19日6时)
- 北京疫情最新消息|5月18日北京新增50例本土确诊病例和5例无症状感染者
- 上海疫情最新消息|5月18日上海新增本土确诊病例82例和本土无症状感染者637例
-

郑州限号|今天是2022年5月19日,郑州限行尾号是4和9
-
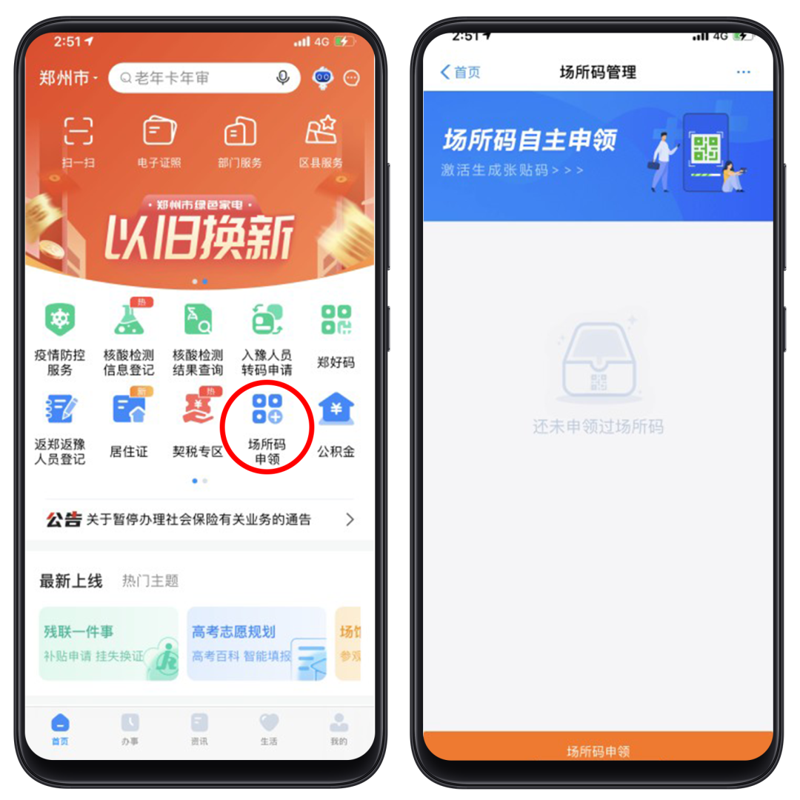
发码总数超68万!郑州市“场所码”覆盖精度再提升
5月18日,记者在郑州市区的多家商超看到,除了商超大门外,商场内部不同楼层、柜台、餐饮店等区域入口处也都张贴了场所码。消费者扫码进入
-

国际博物馆日 河南省南阳市多家博物馆开展线上线下活动
5月17日,河南省南阳市博物馆,游客在观看春秋时期的青铜壶。5月18日是国际博物馆日,河南省南阳市多家博物馆开展线上线下活动,让游客感受
-

南水北调河南段如何成为贯通古今的文脉?
一条渠,绵延千里北上,滋润人间心田。2014年12月12日,南水北调中线工程正式通水。从此,甘甜可口的长江水奔腾不息地流经1432公里,流进千
-

奋战39天 河南省援沪核酸检测医疗队凯旋
5月14日下午,在上海疫情防控一线奋战39天,总计圆满完成130万管核酸检测任务的河南省援沪核酸检测医疗队队员乘坐飞机回到郑州,受到来自省
X 关闭
X 关闭